
Использование RAG, FineTuning и LLM закрытом корпоративном контуре в закрытом корпоративном контуре. В этой статье расскажем о том, как разместить и использовать Виртуальную лабораторию HealthOS в закрытом корпоративном контуре с учётом ее возможностей в области RAG, FineTuning и LLM. Использование Виртуальной лаборатории в закрытом контуре необходимо для избежания утечек конфиденциальной информации за границы определенного периметра.
Определения
В первую очередь определим понятия, которые в дальнейшем будем использовать в этой статье.
Закрытый корпоративный контур — это корпоративная локальная сеть (интранет), которая не имеет выхода в интернет, либо этот выход ограничен правами доступа конкретных пользователей.
LLM — это аббревиатура от словосочетания Large Language Model, — дословный перевод «большая языковая модель» (БЯМ). После появления большие языковые модели изменили обработку естественного языка благодаря своим расширенным возможностям и высокому качеству результатов. Такие модели обучают на огромных наборах данных, по этому они формируют весьма полные модели реального мира. Из-за этого модели способны выполнять широкий спектр задач, перевод с одного языка на другой, обобщения, ответы на вопросы и генерация текста. Однако, не смотря на то, что LLM являются мощным инструментом, они не готовы работать с конкретными корпоративными задачами, так как при обучении не были использованы корпоративные документы.
RAG — это аббревиатура от трёх понятий — «Retrieval», «Augmented» и «Generation». В целом, RAG — это метод использования большой языковой модели, когда пользователь пишет свой вопрос, а система «подмешивает» к вопросу дополнительную информацию из доверенного источника и подает на вход большой языковой модели и запрос и дополнительную информацию. Такой метод позволяет предложить пользователю более полный и точный ответ, содержащий информацию, которая была недоступна большой языковой модели при её обучении и точной настройке (FineTuning).
Retrieval — это поиск и извлечение информации на основе выбранной метрики семантической близости. Этот компонент Виртуальной лаборатории отвечает за поиск и извлечение информации. Название компонента на схеме — «Семантический поиск».
Augmented — это дополнение запроса пользователя найденной в базе данных векторов информацией. Этот компонент Виртуальной лаборатории, который отвечает за компоновку найденной в базе данных векторов информации, называется — «Подготовка контекста».
Generation — это генерация ответа пользователю, с учетом ответа, полученного от большой языковой модели, и информации, дополнительно найденной в базе данных векторов. Этот компонент Виртуальной лаборатории представляет собой точно настроенную большую языковую модель и отвечает за окончательную генерацию ответа пользователю. Название компонента на схеме — «Подготовка ответа».
FineTuning — это процесс «дообучения» LLM на основе закрытого набора документов, который обеспечивает адаптацию предварительно обученной LLM к специализированным внутрикорпоративным задачам. Путём дообучения, или, дословно, «точной настройки модели», на небольшом закрытом наборе документов или корпусе обучающих примеров, специфичных для конкретной корпоративной области, обеспечивается ощутимое улучшение результатов LLM при выполнении специфичных задач, при сохранении общих языковых возможностей модели. Например, точная настройка LLM для анализа тональности текстов повышает точность результатов анализа на 10 процентов. Процесс точной настройки организован таким образом, что документы, участвующие в дообучении, не выходят за границы закрытого контура, что исключает утечку информации.
Схема работы
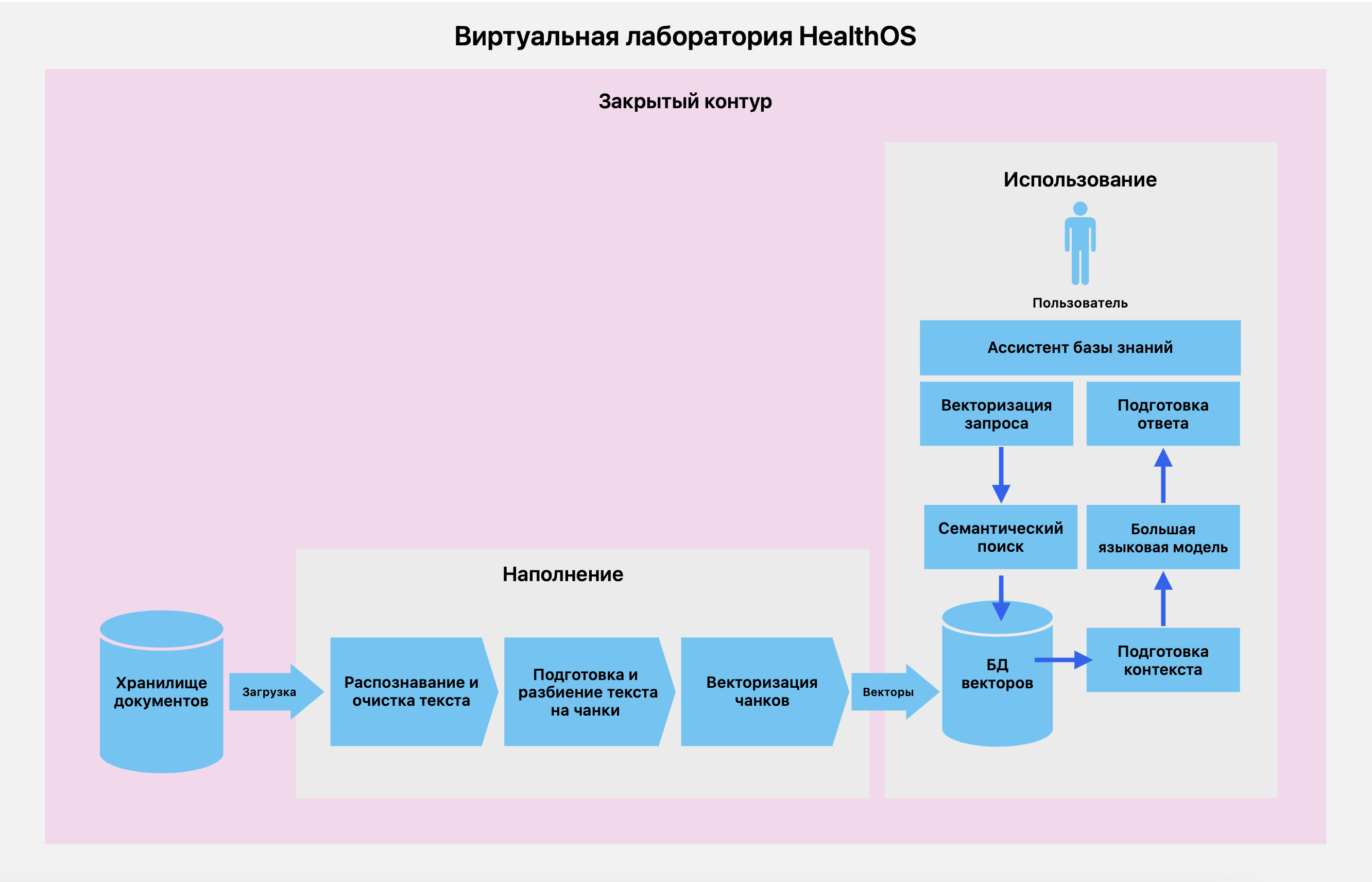
Схема использования большой языковой модели с точной настройкой и RAG в закрытом корпоративном контуре изображена на рисунке и происходит следующим образом.
В зависимости от размера хранилища документов и стоящих перед Виртуальной лабораторией задач, для повышения качества работы компонентов «Семантический поиск» и «Подготовка контекста» может быть использована мультиагентная схема. В такой схеме каждый агент представляет собой автономный компонент, который инициализирован отличными от других компонентов параметрами, что даёт ему некоторую степень отличия, что позволяет выполнять семантический поиск и подготовку контекста с некоторым контролируемым разнообразием. В целом, для некоторых условий, мультиагентная схема обеспечивает лучшее качество результатов обработки запросов пользователей.
Наполнение
Наполнение базы знаний корпоративными документами происходит в непрерывном режиме, по мере появления новых документов или появления новых версий документов.
Этапы наполнения
- Распознавание и очистка текста. На данном этапе отсканированные документы в форматах TIFF или PDF, либо документы в текстовых форматах, таких как Word, Excel, Power Point, RTF, ODF, предварительно сохраненные на файловом сервере, подаются на вход системе. Система сканирует файловый сервер, получает и запоминает полученные версии файлов. После получения, в зависимости от формата файла и качества текста в нем, система пытается извлечь из документа фрагменты текста и склеить из них предложения.
- Подготовка и разбиение текста на чанки. Система получает предложения, фомирует из них текст документа, затем разбивает текст документа на чанки (специально подготовленные фрагменты текста) и передаст их для дальнейшей векторизации.
- Векторизация чанков. Система получает чанки, векторизует их, и сохраняет в базе данных векторов. При сохранении вектора ассоциируются с документом или версией документа, которую система получила на входе.
Использование
Использование базы знаний происходит в любой момент времени, после того, как прошла точная настройка большой языковом модели и она наполнена корпоративными документами.
Порядок работы системы при использовании
- Пользователь в текстовом интерфейсе ассистента базы знаний формирует запрос к системе. Как правило, запрос пользователя к большой языковой модели называют «промпт».
- Запрос векторизуется и переправляется в компонент семантического поиска.
- Компонент семантического поиска получает из базы данных векторов информацию, семантически соответствующую запросу.
- Блок полученной из векторной базы данных информации направляется в компонент подготовки контекста. После подготовки, контекст и запрос направляются в большую языковую модель.
- Большая языковая модель получает запрос и контекст, а далее генерирует текст ответа на запрос с учётом контекста. Текст ответа на запрос передается в компонент подготовки ответа.
- Компонент подготовки ответа получает контекст запроса, а также текст ответа большой языковой модели. Далее этот компонент генерирует окончательный текст ответа на запрос, который отправляется пользователю.
Сценарии
Типовые сценарии использования Виртуальной лаборатории в закрытом корпоративном контуре.
Рекомендации
Виртуальная лаборатория может использоваться для рекомендаций на основе предпочтений пользователя, которые он сообщил системе. Например, система может рекомендовать регламенты, инструкции, спецификации или статьи на основе интересов пользователя, которые были определены в рамках предыдущих взаимодействий с системой. Система анализирует запросы и определяет, какие темы интересны пользователю, и на основе этого предлагает соответствующие рекомендации.
Оценка качества документов
Виртуальная лаборатория может использоваться для оценки качества корпоративных документов. Например, система анализирует тексты и определяет, насколько они полны, информативны или полезны, с точки зрения соответствия информации в запросах пользователя. Система может использовать различные метрики и алгоритмы для оценки качества документов и предоставлять пользователю информацию о том, насколько документ соответствует его требованиям.
Генерация текста документов
Виртуальная лаборатория может использоваться для генерации текста документов. Например, система может создавать тексты на основе заданного шаблона документа, краткого описания или темы. Система может использовать различные методы генерации текста, такие как генеративное моделирование или генерирующие состязательные сети, чтобы создавать уникальные и интересные тексты.
Анализ тональности документа
Виртуальная лаборатория может использоваться для анализа тональности текста документа. Например, система может определить, является ли текст положительным, отрицательным или нейтральным. Система может использовать различные методы анализа тональности, такие как анализ лексики, анализ синтаксиса или анализ контекста, чтобы определить тональность текста конкретного документа.
Классификация документов
Виртуальная лаборатория может использоваться для классификации документов. Например, система может определить, к какой категории или шаблону относится документ. Набор категорий и шаблонов определяется при формировании локальной базы знаний и точной настройке.
Поиск документа или ответа на вопрос
Виртуальная лаборатория может использоваться для поиска документа или ответа на вопрос. Например, система может искать ответ на конкретный вопросы или искать документ с ответом на вопрос, в зависимости от текста запроса пользователя. Набор документов и возможность ответов на конкретные вопросы на основе корпоративных документов определяются при формировании локальной базы знаний и точной настройке.
Пояснение документа
Виртуальная лаборатория может использоваться для пояснения содержимого документа. Например, система может на основе запроса проанализировать тексты и извлечь главные идеи, факты или аргументы из некоторого набора документов, соответствующих теме или формулировке запроса. Набор документов и возможность пояснения их содержимого определяются при формировании локальной базы знаний и точной настройке.
Перевод документов
Виртуальная лаборатория может использоваться для перевода текста документа с русского языка на английский. Перевод на языки кроме английского необходимо обсуждать и прорабатывать отдельно.
Исправление ошибок и улучшение текста
Виртуальная лаборатория может использоваться для исправления ошибок и улучшения текста путём переформулирования предложений с удалением шума и форматированием текста в заданном стиле.
Статья создана с помощью большой языковой модели. Для получения консультаций по работе Виртуальной лаборатории — пишите на sales@rtlab.ru, указав в письме «Консультация по использованию Виртуальной лаборатории».