
Проблема недоверия ИИ вышла за рамки профессиональных кругов и начинает волновать широкую общественность. Сегодня разрабатываются соответствующие манифесты, а из лабораторий выходят программные платформы, реализующие положения этих манифестов. Что такое доверенный ИИ и как эта концепция может быть реализована в медицине?
Общественность всерьез озабочена проблемой недоверия ИИ, уже особенно остро проявляемой в областях с высокой социальной значимостью и ответственностью, например, медицине в целом и в сфере поддержки принятия врачебных решений в реаниматологии, нейрореабилитологии, кардиологии и хирургии, в частности. В чем суть концепции доверенного ИИ и как с помощью системы HealthOS можно решить проблему недоверия ИИ в медицине? В этой статье — ответы на эти вопросы.
Общие положения
Доверенный ИИ — это концепция разработки и эксплуатации систем искусственного интеллекта, гарантированно обладающих свойствами надежности, безопасности, эффективности, продуктивности, прозрачности, конфиденциальности, справедливости и этичности получаемых результатов. Все это предполагает подотчетность соответствующих решений, созданных в доверенной среде разработки и эксплуатации, в рамках концепции доверенного продукта в составе платформы, на основе доверенных алгоритмов, доверенных карт знаний, аксиоматического обучения, доверенной среды кодогенерации и доверенного GraphRAG (Graph-based RAG) – метода анализа и генерации информации, основанного на графовом подходе с дополненным извлечением данных из внешних источников (Retrieval Augmented Generation, RAG).
Создание и использование доверенного ИИ в медицине включает в себя разработку, внедрение, использование и улучшение ИИ в диагностике, лечении, реабилитации, уходе за пациентами, обеспечении лекарствами, контроле качества медпомощи и других областях. Все это образует область цифровизации медицинского центра на основе платформы доверенного ИИ (Рис.1).
 Рис. 1. Цифровизация медицинского центра на основе платформы доверенного ИИ
Рис. 1. Цифровизация медицинского центра на основе платформы доверенного ИИ
Область цифровизации состоит из двух контуров обработки информации: контура исследований и разработок («Контур R&D») и контура эксплуатации кибер-физических систем («Контур КФС») [1]. Первый размещается в облаке на основе катастрофоустойчивой конфигурации ЦОД, а второй на производственной площадке на мощностях одного вычислительного кластера или их федерации: в стационаре, амбулатории, автомобильном телемедицинском модуле, полевом хирургическом модуле и т.д. С одним контуром R&D может быть интегрировано несколько контуров КФС.
Ученые, аналитики и разработчики подписываются на продукты в зоне подписок, получают доступ к данным продуктов, ведут разработку производных продуктов в виртуальной лаборатории с помощью специализированных средств инструментальной зоны, а при помощи зоны автоматизации операций размещают вычислительные задания в зоне расчетов и получают отчеты с выявленными рисками и метриками качества своих продуктов из зоны контроля рисков. В контуре R&D (рис. 2) разрабатываются тезаурусы и карты знаний, которые загружаются в контур КФС (рис. 4) посредством интеграции фабрики данных, расположенной в разных контурах.
Контролеры риска подписываются на соответствующие продукты, получают доступ к данным продуктов, ведут разработку производных продуктов по контролю рисков в виртуальной лаборатории с помощью специализированных средств инструментальной зоны, а при помощи зоны автоматизации операций размещают вычислительные задания в зоне контроля рисков, при этом продукты по контролю рисков получают доступ к данным мониторинга курируемых продуктов. В итоге контролеры риска получают отчеты с метриками качества курируемых продуктов и выявленных рисков.
Менеджеры данных выполняют операции по импорту, учету и верификации качества дата-продуктов в зоне учета и контроля качества данных [2]. Дата продукты получаются из подсистемы управления экспортом данных контура КФС (рис. 3). Администраторы безопасности выполняют операции по управлению доступом пользователей к ресурсам платформы при помощи подсистемы управления доступом. Администраторы защищенности выполняют задачи по комплексному анализу рисков платформы и продуктов в составе платформы, включая специфические риски ИИ.
После завершения приемо-сдаточных испытаний продукта в составе платформы размещается в соответствующем магазине [3]: данных, знаний и навыков.
 Рис. 2. Архитектура контура R&D
Рис. 2. Архитектура контура R&D
Лечащие или дежурные врачи, медицинские сестры и врачи-специалисты используют ассистент для взаимодействия с подсистемой поддержки врачебных решений. Врачи-методисты и контролеры качества используют конструктор для взаимодействия с подсистемами управления семантикой и протоколами. Врачи-диагносты при помощи диагностического или лабораторного оборудования выполняют исследования различных аспектов состояния здоровья пациентов. Дежурные или лечащие врачи при помощи медицинского оборудования выполняют пациентам мероприятия интенсивной терапии. Медсестры при помощи медицинского оборудования выполняют пациентам физиотерапевтические мероприятия. Дежурные или лечащие врачи и медсестры при помощи медицинского оборудования подключают тяжелых или нестабильных пациентов к непрерывному мониторингу показателей состояния здоровья. Менеджеры данных выполняют операции по экспорту, учету и верификации качества дата-продуктов. Данные для дата продуктов получаются из фабрики данных. Контролеры рисков выполняют задачи по анализу допустимости модельных рисков и выполнения требований со стороны продуктов, связанных с подотчетностью, аудируемостью и прозрачностью продуктов и входящих в их состав моделей машинного обучения. Администраторы безопасности выполняют операции по управлению доступом пользователей к ресурсам контура КФС при помощи подсистемы управления доступом.
 Рис. 3. Архитектура контура КФС
Рис. 3. Архитектура контура КФС
Прозрачный и подотчетный ИИ
Подотчетный ИИ (Accountable AI) – это, прежде всего, объяснимый (Explainable AI) и интерпретируемый ИИ (Interpretable AI). Первый предусматривает разработку методов, позволяющих объяснить результаты работы моделей ИИ (глубинные нейронные сети и пр.) и понять, как было получено то или иное решение. Интерпретируемый ИИ фокусируется на создании изначально понятных и легко интерпретируемых моделей, использующих простые алгоритмы: деревья решений, линейные модели и т.п., что делает прозрачным процесс принятия решений.
Подотчетный ИИ акцентирует внимание на ответственности и полной ясности всех процессов разработки и использования систем ИИ. Это означает, что такие системы должны быть так спроектированы, чтобы их в любой момент времени и на любом этапе их работа могла быть проверена, объяснена и подвергнута аудиту на соответствие требованиям контроля уровня качества, предвзятости и рисков ИИ, этическим и юридическим нормам [1]. Подотчетный ИИ охватывает все аспекты ответственности и прозрачности в разработке и использовании ИИ, а интерпретируемый и объяснимый сосредоточены на конкретных аспектах понимания и прозрачности моделей ИИ.
Понимание интерпретируемого ИИ включает: алгоритмическую подотчетность (прозрачность), право на объяснение и модель белого ящика (White-box model).
Алгоритмическая подотчетность включает в себя возможность отслеживать ошибки и предвзятости в алгоритмах, а также требования по разработке механизмов для их исправления и предотвращения. Это особенно важно в контексте этических и социальных последствий применения ИИ в таких чувствительных областях, как здравоохранение, финансы, правосудие, управление инженерной инфраструктурой и других областях, где принятые с помощью ИИ решения могут повлиять на жизнь людей.
Право на объяснение – индивидуальное право пользователя ИИ-системы на получение информации, гарантирующее, что в процессе исполнения задач система протоколирует свою работу, включая эпизоды принятия решений и по запросу формирует юридически-значимое обоснование результатов принятых решений. Например, в случае отказа банка в выдаче кредита, должен формироваться отчет и справка с указанием причин. Право на объяснение может регламентироваться законодательно либо в виде профессионального стандарта.
Модель белого ящика позволяет разработчикам и пользователям понимать и контролировать все внутренние процессы и механизмы работы моделей ИИ с целью интерпретации процесса преобразования входных данных в результаты работы модели. Модель белого ящика определяет допустимые классы алгоритмов: линейная регрессия, деревья решений, Generalized Additive Models (GAMs) и уровень доверия к обучающей выборке, обычно достигаемый путем использования аксиоматического обучения на основе графов знаний, валидированных экспертами. Разработчики имеют полный доступ к исходному коду модели и алгоритмам, используемым для обучения и принятия решений, а также к обучающим данным. Модель белого ящика позволяет анализировать работу моделей машинного обучения, выявлять потенциальные проблемы и улучшать их производительность, однако требует от разработчика глубоких знаний. Такая модель обычно используется в медицинских системах поддержки принятия решений и в областях, где требуется высокая степень доверия и прозрачность. Ограничения алгоритмов машинного обучения для в модели белого ящика компенсируются автоматизацией процессов разработки ИИ-систем на основе графов знаний с помощью автогенераторов, строящих ансамбли моделей, которые при получении входных данных документируют весь процесс преобразования признаков по всей цепочке. Далее, задокументированный процесс может быть представлен в виде пояснительного отчета, в котором однозначно представлен весь процесс преобразования входных данных в результат.
Доверенная среда разработки
Концепция доверенной среды разработки направлена на создание условий, при которых создание и эксплуатация систем ИИ происходит с соблюдением стандартов отбора повторно используемых компонентов, безопасности, надежности, эффективности, продуктивности, прозрачности, подотчетности, конфиденциальности, справедливость, этичности и аудита на соответствие требованиям, включая качество данных, устойчивости к угрозам и соблюдения права на объяснение.
Повторно используемые компоненты – фрагменты кода и документации, модули, библиотеки, шаблоны проектирования, файлы конфигураций, обучающие и тестовые корпуса, протоколы карт знаний, и другие компоненты, которые могут использоваться без переделки в различных проектах. Отбор компонентов обеспечивается на основе критериев качества, безопасности и соответствия требованиям. При этом выполняется регулярное обновление и проверка компонентов на предмет их актуальности, безопасности и соответствия стандартам.
Безопасность среды разработки обеспечивается за счет шифрования данных для защиты от несанкционированного доступа; аутентификации и авторизации пользователей для контроля доступа к ресурсам; мониторинга и обнаружения вторжений для предотвращения кибератак.
Надежность среды разработки и результатов обеспечивается путем тестирования и отладки кода для выявления и устранения ошибок; резервного копирования данных для восстановления после сбоев; использования отказоустойчивых систем для минимизации простоев; размещения оборудования в ЦОД разных провайдеров; применения аксиоматического обучения для генеративного ИИ, участвующего в кодогенерации.
Эффективность среды разработки обеспечивается за счет оптимизации алгоритмов и структур данных для повышения производительности; автоматизации массовых задач для сокращения времени разработки; использования облаков для масштабирования ресурсов.
Продуктивность среды разработки обеспечивается благодаря кодогенерации на основе специализированных средств и генеративных моделей ИИ для ускорения процесса разработки, автоматического тестирования и сборки с целью минимизации ошибок, интеграции с системами управления проектами для автоматического отслеживания прогресса.
Прозрачность среды разработки обеспечивается за счет публикации отчетов о результатах тестирования и аудите процессов и сред разработки независимыми экспертами, предоставления доступа к исходному коду и документации заинтересованным сторонам, взаимодействия с сообществом разработчиков для обмена опытом и знаниями.
Подотчетность среды разработки обеспечивается за счет ведения журналов событий для аудита действий пользователей и систем; проведения аудита безопасности и соответствия стандартам; предоставления отчетности о результатах аудита заинтересованным сторонам.
Конфиденциальность среды разработки обеспечивается за счет предоставления доступа к защищаемым данным только авторизованным пользователям; шифрования данных при передаче и хранении; соблюдения законодательства о защите персональных данных.
Справедливость среды разработки обеспечивается за счет разработки алгоритмов без предубеждений и дискриминации прав и возможностей пользователей или лиц, которых затрагивают результаты работы ИИ-систем; систематического мониторинга и корректировки алгоритмов для предотвращения каких-либо аспектов проявления несправедливости.
Этичность среды обеспечивается за счет соблюдения принципов уважения к правам человека и его законным возможностям, исключения использования ИИ для ограничения прав и возможностей людей.
Аудит среды разработки на соответствие требованиям обеспечивается путем идентификации и документирования всего установленного и используемого в среде разработки ПО; проверки и оценки лицензий на ПО; оценки способов использования ПО и обеспечения соблюдения требований лицензий; выявление потенциальных рисков безопасности, связанных с программным обеспечением, включая известные уязвимости в компонентах с открытым исходным кодом; документирования результатов аудита, с указанием нарушений и предоставлением рекомендаций по их исправлению.
Аудит качества данных обеспечивается за счет их проверки перед использованием, маркировки и, при необходимости, удаления выбросов и иных аномалий, а также применения методов очистки и нормализации данных.
Среда разработки должна быть устойчива к угрозам, включая угрозы манипуляции данных, что обеспечивается за счет обучения моделей ИИ на разнообразных, эталонных для различных рисков искажениях данных, а также использования методов обнаружения и предотвращения манипуляций данными, и регулярного обновления программного кода и файлов весов моделей машинного обучения для учета новых угроз и изменений в данных.
Соблюдение права на объяснение обеспечивается за счет использования интерпретируемых моделей ИИ; создания визуальных представлений данных и процессов, происходящих внутри модели ИИ; генерации высказываний на естественном языке, объясняющих решения модели на основе логических правил или эвристик, которые используются для принятия решений; идентификации и локализации ошибок в работе модели ИИ, что позволяет лучше понять причины принятия неправильных решений; применения специализированных методов объяснения, таких как LIME (Local Interpretable Model-agnostic Explanations) или SHAP (SHapley Additive exPlanations), позволяющих объяснить результаты вычислений модели на уровне отдельных входных признаков; предоставления пользователям возможности интерактивно взаимодействовать с моделью ИИ, задавать вопросы и получать объяснения на естественном языке; разработки обучающих материалов и документации, объясняющих работу модели; внедрения механизмов аудита и контроля, которые позволяют проверить и подтвердить объяснения, предоставляемые моделью ИИ; сбора обратной связи от пользователей о том, насколько понятны и приемлемы объяснения, предоставляемые моделью ИИ; разработки и внедрения стандартов и регулятивных требований, обязывающих разработчиков ИИ-систем обеспечивать право на объяснение.
Доверенный продукт в составе платформы
Рост сложности решений на основе ИИ приводит к укрупнению соответствующих систем и их преобразованию в платформы, в которых продукты интегрированы с базами данных, API, пользовательскими интерфейсами, панелями мониторинга и прочими сервисами. Это позволяет продуктам получать доступ к большим объемам разнообразных данных, разделять общие ресурсы, а также взаимодействовать с другими продуктами и сервисами платформы.
Доверенный продукт в составе платформы состоит из двух независимых частей: «Функциональный ИИ» и «Контроль риска» – обеспечение функциональных требований и контроль подотчетности, прозрачности, защита от угроз ИИ и управление модельным риском продукта соответственно (см. Таблицу).
Таблица. Этапы жизненного цикла доверенного продукта в составе платформы.
| № | Этапы ЖЦ доверенного продукта в составе платформы | ||
| Название этапа | Решаемые задачи | ||
| Функциональный ИИ | Контроль риска | ||
| 1 | Анализ целей, задач и контекста | Идентификация целей использования ИИ и задач, которые должен выполнять ИИ.
Анализ среды, в которой будет использоваться ИИ, включая технические ограничения, законодательные требования и ожидания пользователей. |
Идентификация целей контроля модельного риска ИИ и задач, которые должен выполнять контроль.
Анализ среды, в которой будет использоваться ИИ, включая оценку приоритетов угроз, технических ограничений, законодательных требований и ожиданий пользователей. Определение модели угроз ИИ. |
| 2 | Определение требований | Определение функциональных требований к ИИ.
Определение нефункциональные требований к ИИ: требования к надежности работы в условиях неопределенности, безопасности данных и конфиденциальности информации, эффективности использования вычислительных ресурсов и энергии, продуктивности и повышения производительности труда пользователей, прозрачности функционирования и принятия решений, конфиденциальности механизмов защиты и контроля доступа к данным, подотчетности и надзору за поведением и результатами работы ИИ, справедливости и отсутствию предвзятости, этичности взаимодействия между людьми и ИИ. |
Определение требований к защите от угроз ИИ: аудиту для выявления уязвимостей, устойчивости к атакам и манипуляциям с данными, использование водяных знаков для защиты интеллектуальной собственности, периодичности актуализации модели угроз.
Определение требований к контролю модельного риска: прозрачности и объяснимости ИИ, валидации на различных наборах данных для обобщения и точных предсказаний, верификации на соответствие целям и задачам, мониторинг поведения и результатов работы для выявления ошибок и отсутствия предвзятости, аудита для выявления потенциальных проблем, адаптивности к изменениям в данных и окружающей среде, целевым показателям качества для поддержания точности и актуальности, а также качеству входных данных в режиме использования. |
| 3 | Разработка карты знаний продукта и базы знаний | Построение тезауруса карты знаний. Определение терминов и отношений между ними, а также синонимов, антонимов, сокращений и других атрибутов терминов.
Построение структуры карты знаний. Определение протоколов преобразования признаков и их атрибутов, ассоциация признаков и атрибутов с терминами тезауруса. Сбор информации из экспертных источников для уточнения карты знаний. Источники документов — веб-страницы, базы данных, документы. Собранные документы загружаются в базу знаний. Интеграция собранных данных. Объединение разнородных данных в единую структуру карты на основе единого тезауруса. Анализ собранных данных для извлечения новых терминов карты знаний и отношений между ними. Разработка алгоритмов машинного обучения для улучшения качества карты знаний и предсказания новых терминов и связей между терминами. Контроль достоверности. Определение достоверности связей между терминами карты знаний путем классификации триплетов и генерации достоверных высказываний. Генерация достоверных высказываний на естественном языке. Создание правил для генерации высказываний на основе терминов, связей и дополнительной информации, содержащейся в карте знаний. Мониторинг и обновление карты знаний. Отслеживание изменений в реальном мире и обновление карты знаний. |
Построение тезауруса карты знаний модельного риска. Определение терминов и отношений между ними, а также синонимов, антонимов, сокращений и других атрибутов терминов.
Построение структуры карты знаний модельного риска. Определение протоколов преобразования признаков и их атрибутов, ассоциация признаков и атрибутов с терминами тезауруса. Сбор информации из экспертных источников для уточнения карты знаний модельного риска. Источники документов — веб-страницы, базы данных, документы. Собранные документы загружаются в базу знаний модельного риска. Интеграция собранных данных. Объединение разнородных данных в единую структуру карты знаний модельного риска на основе единого тезауруса. Анализ собранных данных для извлечения новых терминов карты знаний модельного риска и отношений между ними. Разработка алгоритмов машинного обучения для улучшения качества карты знаний модельного риска и предсказания новых терминов и связей между терминами. Контроль достоверности. Определение достоверности связей между терминами карты знаний модельного риска путем классификации триплетов и генерации достоверных высказываний. Генерация достоверных высказываний на естественном языке. Создание правил для генерации высказываний на основе терминов, связей и дополнительной информации, содержащейся в карте знаний модельного риска. Доработка карты знаний модельного риска с учетом терминов и их связей, обеспечивающих водяной знак (watermark) ИИ. Мониторинг и обновление карты знаний модельного риска. Отслеживание изменений в реальном мире и обновление карты знаний модельного риска. |
| 4 | Актуализация требований | Актуализация требований к ИИ-системе в процессе и после завершения разработки карты знаний из-за получения новой важной информации. | Актуализация требований к защите от угроз ИИ, и требований к контролю модельного риска в процессе и после завершения разработки карты знаний модельного риска из-за получения новой важной информации. |
| 5 | Разработка дата-продукта | Подбор источников данных.
Первичная оценка качества данных каждого источника. Интеграция данных каждого источника в единую структуру на основе единого тезауруса (ассоциация сущностей в данных с терминами единого тезауруса). Для глубокого анализа качества данных проверяют релевантность, стабильность, однородность и полноту данных. Релевантность означает соответствие данных поставленной задаче, стабильность — наличие необходимых и истинных меток, однородность — единообразие значений всех атрибутов, а полнота — достаточное количество примеров для покрытия всех признаков карты знаний. Подмешивание в дата-продукт обучающих примеров, обеспечивающих водяной знак (watermark) ИИ. Сборка, тестирование и публикация дата-продукта. |
Глубокий анализ дата-продукта на недостатки необходимо проверить релевантность, стабильность, однородность и полноту данных. Релевантность означает соответствие данных поставленной задаче, стабильность — наличие необходимых и истинных меток, однородность — единообразие значений всех атрибутов, а полнота — достаточное количество примеров для покрытия всех признаков карты знаний. Недостатки данных могут быть связаны с ошибками релевантности – неверная маркировка признаков, либо использование маркеров, которые не определены в карте знаний, ошибками однородности данных и достоверности разметки, неоднородностью атрибутов признаков и слабым покрытием примеров.
Разработка сценариев генерации злонамеренных тестовых запросов и обучающих вставок на основе недостатков релевантности, стабильности, однородности и полноты данных дата-продукта. Разработка сценариев генерации обучающих примеров, проверяющих устойчивость водяного знака (watermark) ИИ. Разработка дата-продукта контрольной модели: интеграция данных источников в единую структуру на основе единого тезауруса модельного риска, сборка, тестирование и публикация дата-продукта контрольной модели. |
| 6 | Разработка модели-кандидата | Анализ качества данных дата-продукта.
Подбор подходящих алгоритмов для моделей-кандидатов. Разработка моделей-кандидатов на основе функциональных и нефункциональных требований к ИИ, а также требований к прозрачности и объяснимости ИИ. Анализ устойчивости моделей-кандидатов к данным. Выбор наилучшей модели-кандидата. |
Анализ качества данных дата-продукта контрольной модели.
Подбор подходящих алгоритмов для контрольных моделей-кандидатов. Разработка контрольных моделей-кандидатов на основе требований к защите от угроз ИИ и требований к контролю модельного риска. Анализ устойчивости контрольных моделей-кандидатов к данным. Выбор наилучшей контрольной модели-кандидата. |
| 7 | Оптимизация модели-кандидата | Оптимизация модели-кандидата с точки зрения потребностей в вычислительных ресурсах.
Анализ устойчивости оптимизированной модели-кандидата к вычислительной нагрузке. Шифрование исполняемых файлов и файлов весов и активаций модели-кандидата для исключения злонамеренных подмен и вставок. |
Оптимизация контрольной модели-кандидата с точки зрения потребностей в вычислительных ресурсах.
Анализ устойчивости контрольной модели-кандидата к вычислительной нагрузке. Шифрование исполняемых файлов и файлов весов и активаций контрольной модели-кандидата для исключения злонамеренных подмен и вставок. |
| 8 | Контроль качества модели-кандидата | Анализ модели-кандидата на соответствие функциональным и нефункциональным требованиям к ИИ, а также требованиям к прозрачности и объяснимости ИИ.
Проверка защиты модели-кандидата от неавторизованного доступа. |
Анализ модели-кандидата на предмет уязвимостей и устойчивости к данным предполагает три категории проверок. Тестирование модели-кандидата на уязвимости обучения, такие как переобучение, перекос данных в обучающей выборке и злонамеренные вставки. Тестирование модели-кандидата на устойчивость к данным, включая атаки на вход и выход. Тестирование защити от неавторизованного доступа. |
| 9 | Проведение ПСИ модели-кандидата | ||
| 10 | Размещение модели на продуктивной среде | Разработка и отладка сценария развертывания модели.
Автоматизация исполнения сценариев развертывания модели. |
Разработка и отладка сценария развертывания контрольной модели.
Автоматизация исполнения сценариев развертывания контрольной модели. |
| 11 | Контроль качества модели | Анализ дрейфа данных.
Проверка модели на соответствие функциональным и нефункциональным требованиям, а также требованиям к прозрачности и объяснимости ИИ. |
Проверка соблюдения требований к защите от угроз ИИ.
Проверка соблюдения требований к контролю модельного риска. Проверка защиты модели от неавторизованного доступа. |
| 12 | Разработка новых версий модели в рамках релизного цикла | Сбор и анализ открытой информации, получение обратной связи от пользователей, уточнение и добавление задач в бэклог продукта.
Планирование состава релиза. Выполнение задач 1-10. |
Сбор и анализ открытой информации, сбор и анализ тестирования на уязвимости, уточнение и добавление задач в бэклог контрольной модели.
Планирование состава релиза. Выполнение задач 1-10. |
| 13 | Завершение разработки и вывод из эксплуатации продукта | Определение стратегии вывода продукта из эксплуатации, включая сроки и порядок действий.
Прекращение поддержки и технического обслуживания продукта. Деактивация компонентов продукта. Сохранение целостности затрагиваемых процессов после вывода продукта из эксплуатации. Архивация данных и обеспечение доступа к данным и знаниям, накопленным продуктом, для последующего анализа и использования. Обеспечение того, что после вывода продукта из эксплуатации его окружение остается в стабильном и безопасном состоянии. |
Контроль состояния окружающей среды в процессе вывода продукта из эксплуатации на предмет стабильности, безопасности и согласованности. |
Доверенный алгоритм
Речь идет об алгоритмах, разработанных с учетом строгих стандартов безопасности, надежности и эффективности, предназначенных для использования в доверенных средах, требующих усиленной защиты данных и процессо, а также снабженных механизмами аудита и отслеживания параметров, результатов операций преобразования для отслеживания происхождения данных и мониторинга процессов их обработки.
Доверенные алгоритмы – это алгоритмы шифрования, аутентификации, цифровой подписи и хеширования. Все они широко используются в криптографии, сетевой безопасности, управлении доступом и других областях, требующих высокого уровня защиты данных и процессов.
Основные отличия доверенных алгоритмов ИИ:
- Прозрачность. Доверенные алгоритмы уделяют особое внимание разработке моделей, которые могут быть легко интерпретированы и объяснены, включая обеспечение прозрачности процесса обучения и работы модели, что позволяет пользователям лучше понять, как модель принимает решения.
- Доказательство корректности. В отличие от общих доверенных алгоритмов, здесь применяются специфические методы, позволяющие доказать корректность работы модели (LIME, SHAP и др.). В состав методов доказательства корректности также входит проверка на наличие ошибок или аномалий во входных данных и в данных обучающего корпуса.
- Подотчетность. Предоставление аудитору возможности самостоятельно убедиться в корректности работы алгоритма за счет доступа к отчетам аудита с доказательствами корректности работы алгоритма.
- Защита данных и моделей. Доверенные алгоритмы создают модели, устойчивые к атакам на данные и модели.
- Строгое тестирование и валидация результатов. Доверенные алгоритмы требуют строгого тестирования и валидации моделей перед их передачей в эксплуатацию для гарантирования их надежности и точности. Для этого каждый функциональный алгоритм (реализующий требования к ИИ) сопровождается алгоритмом контроля рисков (реализующий валидацию результатов функционального алгоритма).
- Контроль рисков искажения информации. Доверенные алгоритмы работают только с поименованными признаками, ассоциированными с терминами единого тезауруса, получают на вход один набор поименованных признаков, выполняют операцию преобразования, а на выходе предоставляют другой набор поименованных признаков. Таблица преобразований признаков из одного набора в другой определяется в соответствующем протоколе преобразования признаков, который является неотъемлемой частью карты знаний. В случае, когда доверенный алгоритм получает на вход аналоговые или неструктуриированные данные, параметры качества входного и входных сигналов, а также набор выходных признаков определяются в соответствующем протоколе, который также является неотъемлемой частью карты знаний.
Доверенная карта знаний
Карта знаний — исчерпывающее формальное описание структуры и параметров вычислительной модели конкретного фрагмента реального мира. Карта отличается от графа знаний тем, что все ее признаки ассоциированы с терминами единого тезауруса. Кроме этого, карта знаний в обязательном порядке содержит полное описание структуры и параметров своей вычислительной модели. Карта знаний может иметь статус доверенной – в этом случае она концептуально, логически и терминологически интегрирована в прикладное знание, соответствует нормативной документации и этическим нормам, а также легализована путем получения положительного заключения авторитетной некоммерческой ассоциации, научного или медицинского центра, в которых имеются «Комитет по этике» и «Ученый совет».
Концепция карт знаний была предложена компанией РТЛАБ в открытой экосистеме обмена научными знаниями для разработки доверенного ИИ в реаниматологии. Карты знаний реализованы на платформе доверенного медицинского ИИ HealthOS, позволяющей автоматизировать процессы их создания и совместного использования в областях с высокой социальной значимостью и ответственностью. Примеры карт знаний из реаниматологии: «Санитарно-эпидемиологические и гигиенические мероприятия в ОРИТ (Отделение реанимации и интенсивной терапиии)»; «Сестринские манипуляции в ОРИТ»; «Прогноз, купирование и профилактика фибрилляции и трепетания предсердий».
Медицинская карта знаний состоит из нормативной документации, протоколов диагностики и лечения, протоколов выполнения процедур и манипуляций, протоколов определения признаков (Рис. 4).
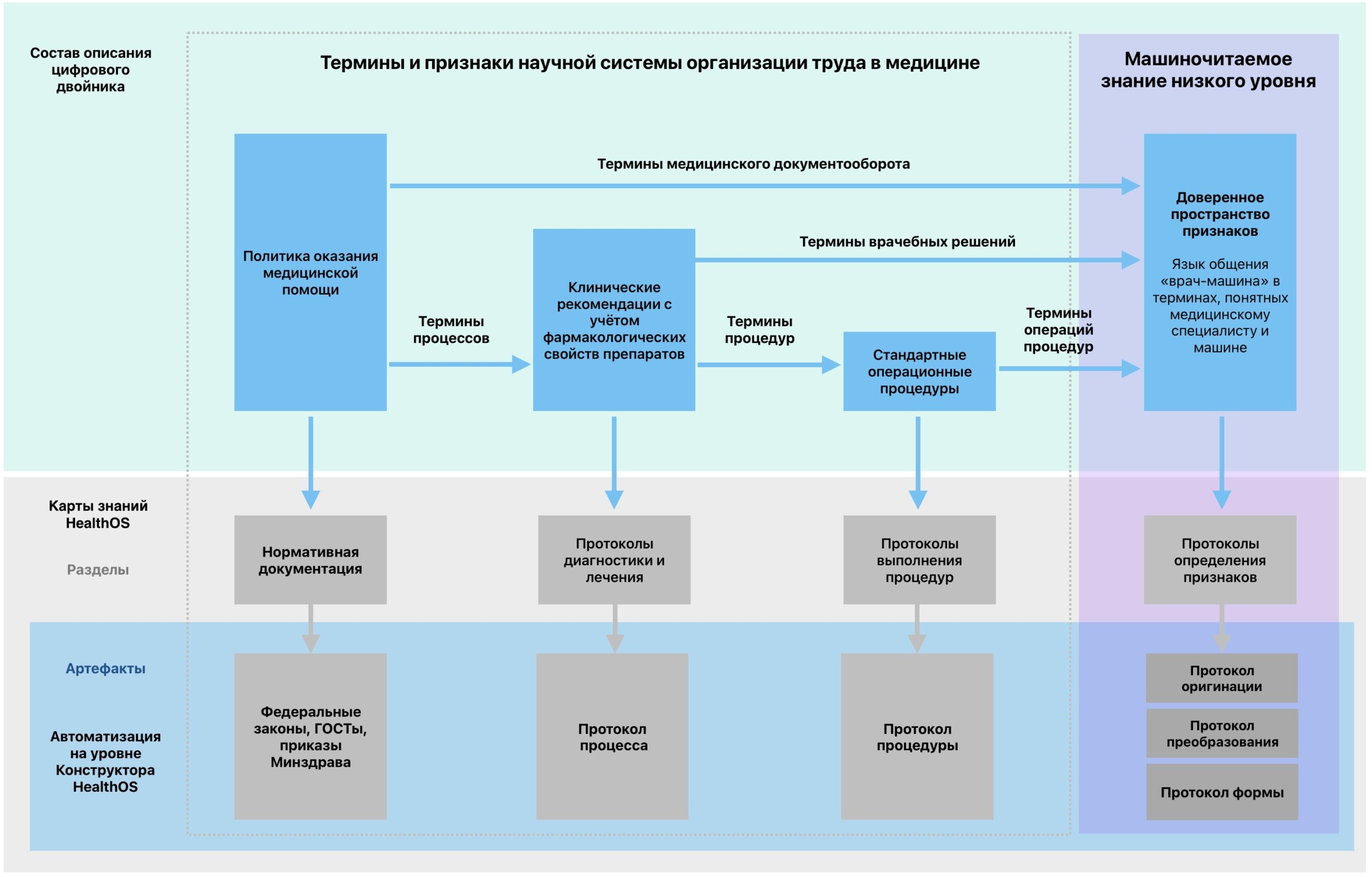 Рис. 4. Медицинская карта знаний
Рис. 4. Медицинская карта знаний
Карты знаний применяются при разработке моделей машинного обучения и общего программного обеспечения – они снижают вероятность ошибок и повышают уровень абстракции при создании ПО. При разработке моделей машинного обучения карты знаний применяются для генерации обучающих высказываний и тестовых примеров при аксиоматическом обучении. При разработке общего ПО карты знаний применяются в качестве входных программ для специализированных кодогенераторов – для различных аспектов кодогенерации разрабатываются специализированные предметно-ориентированные языки верхнего уровня (domain-specific language, DSL), обеспечивающие интеграцию карт знаний с кодогенераторами общего назначения в форме непрерывного конвейера кодогенерации.
Аксимоматическое обучение
Аксиоматическое обучение – обучение ИИ, основанное на предположении, что знания могут быть представлены в виде набора аксиом, из которых с помощью правил вывода можно вывести истинные утверждения. В аксиоматическом обучении ИИ важную роль играют графы знаний, обеспечивая удобный и структурированный способ представления знаний в виде набора узлов и ребер. В процессе обучения, аксиомы могут быть представлены в виде логически верных утверждений, созданных генератором обучающего корпуса путем трансляции узлов и связей между узлами графа знаний в логически и семантически согласованные строки текста (истинные утверждения). Использование карт знаний для аксиоматического обучения ИИ позволяет упростить процесс обучения, повысить его эффективность и улучшить качество.
Примеры аксиоматического обучения ИИ:
- Обучение с подкреплением на основе аксиом. Аксиомы используются для формулирования правил поведения агента в среде, например «если действие A приводит к состоянию S, то следующее действие должно быть B», где A и B – конкретные действия, а S – состояние среды.
- Аксиоматическое обучение в задачах классификации. Тут аксиомы используются для формулирования правил классификации объектов, например можно сформулировать аксиому «если объект имеет признаки A и B, то он относится к классу C», где A и B – конкретные признаки, а С – класс объекта.
- Аксиоматическое обучение в задачах прогнозирования. В этом случае аксиомы используются для формулировки правил предсказания будущих событий, например «если событие E произошло после события F, то вероятность события G увеличивается», где E, F и G – конкретные события.
Применение аксиоматического обучения в создании доверенного ИИ достаточно перспективно, поскольку обеспечивает строгую логику и последовательность в процессе обучения.
Основные принципы аксиоматического обучения:
- Строгость и последовательность. Аксиоматическое обучение позволяет ИИ следовать строгим правилам и принципам, что критически важно именно для доверенного ИИ, помогая избежать случайных ошибок и предвзятости при принятии решений.
- Прозрачность и объяснимость. Использование аксиом делает процесс обучения ИИ более прозрачным и понятным для человека, что облегчает проверку и аудит алгоритмов, а это важно для обеспечения доверия к системам ИИ.
- Адаптивность и гибкость. Несмотря на строгую структуру, аксиоматическое обучение позволяет ИИ адаптироваться к новым условиям и данным за счет добавления новых аксиом или изменения уже существующих.
- Безопасность. Строгая логика и последовательность аксиоматического обучения помогают предотвратить несанкционированный доступ к данным и алгоритмам, что повышает безопасность систем ИИ.
- Интеграция с другими методами обучения. Аксиоматическое обучение может быть интегрировано с другими методами машинного обучения, такими как GraphRAG, для создания более эффективных и надежных решений.
Доверенная среда кодогенерации
В отличие от обычной среды кодогенерации, доверенная среда акцентирует внимание на безопасности (защите от несанкционированного доступа к исходным данным, шаблонам и метаданным, используемым для генерации кода); контроле версий; — аутентификация и авторизация ; тестировании и верификации; интеграции с системами управления версиями для обеспечения централизованного управления изменениями путем, например интеграции с системами контроля версий, такими как Git; мониторинге и аудите; соответствии стандартам и нормам.
Доверенная среда кодогенерации направлена на обеспечение высокого уровня доверия к процессу генерации кода и его результату, что очень важно при разработке ПО для критически важных приложений.
Автоматическая генерация кода – мощный инструмент, позволяющий существенно улучшить процесс разработки ПО, однако генераторы кода не могут полностью заменить разработчиков.
Доверенный GraphRAG
Технология RAG генерации ответов с дополненным извлечением информации из внешних источников обеспечивает извлечение информации из хранилищ данных и других источников и генерацию текста на ее основе. Основная идея в том, чтобы предоставить языковой модели доступ к дополнительным данным, которые могут помочь ей генерировать более точные и информативные ответы. Процесс RAG начинается с поиска релевантной запросу информации в существующих хранилищах данных: базы данных, энциклопедии, новостные ленты и т.д. Затем информация вместе с вопросом подается на вход языковой модели, которая генерирует ответ, учитывающий все доступные данные. RAG позволяет повысить качество ответов языковых моделей, особенно в тех случаях, когда важна точность и актуальность. Этот метод широко используется в областях, где важно предоставлять пользователям достоверные и полезные сведения, например, в поддержке клиентов, научных исследованиях и образовании.
Метод GraphRAG анализа и генерации текстовой информации, основан на графовом подходе к RAG и использует большую языковую модель (LLM) для автоматического создания графа знаний из набора текстовых документов, полученных из корпоративных хранилищ.
С помощью GraphRAG решаются следующий задачи:
- Формирование структуры текста ответа. GraphRAG формирует граф знаний, полученных из текстов корпоративной базы знаний еще до того, как пользователи начнут задавать вопросы, что позволяет системе предоставлять более точные и информативные ответы.
- Уточнение ответов на глобальные вопросы. Метод GraphRAG эффективно работает при ответах на общие вопросы, касающиеся всего набора документов, например, “Какие темы затрагиваются в документах конкретного департамента?”.
- Повышение полноты и разнообразия ответов. GraphRAG группирует документы до размера, соответствующего контекстному окну LLM, применяет вопрос к каждой группе для создания ответов на уровне группы, а затем объединяет все релевантные ответы в итоговую общую выдачу. Это позволяет улучшить полноту и разнообразие ответов по сравнению с традиционными методами RAG.
В контексте GraphRAG может быть использовано аксиоматическое обучение для уточнения и расширения графа знаний путем добавления новых сущностей, связей и утверждений на основе аксиом и правил вывода, что позволяет обучать разные специализированные модели на основе доверенных знаний и выверенных экспертных источников (карт знаний), вместо огромного набора неструктурированных документов. В итоге, система ИИ может лучше понимать контекст запросов и предоставлять более точные ответы.
Доверенная среда эксплуатации
Доверенная среда эксплуатации обеспечивает безопасные, контролируемые условия работы системы ИИ за счет надежности аппаратного обеспечения, систем хранения данных, сетевых соединений и облачных сервисов, устойчивых к киберугрозам и обеспечивающих высокую доступность. Прикладное ПО также должно быть защищено от вредоносных атак. Данные, используемые для обучения и работы ИИ должны быть защищены от несанкционированного доступа, утечек и манипуляций. Кроме этого должны быть развернуты системы аутентификации и авторизации, обеспечивающие контроль доступа к ресурсам ИИ. Важное значение имеет мониторинг и аудит, выполняемые с помощью инструментов для отслеживания преобразования данных и активности ИИ, анализа его поведения и выявления потенциальных угроз. Наконец, персонал должен иметь соответствующую квалификацию и сертифицирован.
Создание и поддержание доверенной среды эксплуатации ИИ требует комплексного подхода, включающего технические, организационные и правовые меры.
Платформа доверенного медицинского ИИ
HealthOS [1] — пионер реализации доверенного ИИ в медицине, в которой реализована представленная концепция доверенного ИИ, предназначенная для работы в закрытом контуре и сочетающая в себе принципы графового подхода к анализу и генерации текста с методами аксиоматического обучения генеративного ИИ на основе карт знаний.
HealthOS обеспечивает сбор данных с медицинского оборудования и медицинских записей, идентификацию рисков здоровью пациентов, генерацию событий второго мнения, генерацию летописи и аватара пациента, использование GraphRAG для взаимодействия с летописью в режиме вопрос-ответ. События второго мнения – это подсказки, уведомления, алерты и прогнозы. Летопись — это хронологически согласованное текстовое описание изменения состояния здоровья пациента с учётом фактов оказания медицинской помощи и анализа степени воздействия проводимой терапии. Аватар — это двух- или трехмерная графическая модель пациента в целом или выбранной системы или процесса его тела, предназначенная для AR/VR-гарнитур.
Графовая база данных обеспечивает представление единого тезауруса терминов и карт знаний, а также представление обучающих документов и текстов запросов пользователей в виде сети взаимосвязанных элементов: термины из единого тезауруса, предложения из терминов, абзацы предложений и т.д., что позволяет более эффективно векторизовать и анализировать текстовую информацию, автоматически контролируя риски ее искажения.
В контексте GraphRAG могут использоваться специализированные модели машинного обучения для выполнения векторизации документов и запросов пользователей в виде узлов и связей графа, обогащения запросов на основе графа, систематизации и суммаризации выдачи закрытых источников информации, и пр.
В целом, при создании доверенного ИИ большим потенциалом обладает применение аксиоматического обучения, карт знаний, графового представления закрытых документов, способствуя повышению надежности, прозрачности и безопасности ИИ-систем.
Платформа доверенного медицинского ИИ для автоматизации лечебных процессов в реаниматологии, анестезиологии, кардиологии, хирургии и других областях, а также в научных и клинических исследованиях HealthOS позволяет на порядок повысить эффективность разработки и внедрения в рутинную медицинскую и научную практику доверенного ИИ.
Заключение
Программная платформа, построенная в соответствии с концепцией доверенного ИИ, должна гарантировать предсказуемость свойств продуктов, созданных на ее основе и исполняемых в ее составе: работа без сбоев или ошибок в условиях неопределенности; защита от кибератак; быстрое и точное выполнение задач с использованием доступных ресурсов; максимально возможная производительность труда разработчиков и пользователей; возможность прозрачного контроля над действиями разработчиков и аудит результатов работы ИИ; обеспечение конфиденциальности и защиты собираемых и генерируемых данных; исключение предвзятости и учет интересов всех заинтересованных лиц; соблюдение этических принципов взаимодействия между людьми и системами, направленными на расширение возможностей людей, а не на их ограничение.
Литература
- Александр Прозоров, Дмитрий Волков. Недоверие медицинским данным: проблемы и решение // Открытые системы.СУБД. — 2023. — №4. — С.26-32. URL: https://www.osp.ru/os/2023/04/13057831 (дата обращения: 21.09.2024).
- Сергей Гарбук. Функциональность и безопасность систем искусственного интеллекта: качество данных // Открытые системы.СУБД. — 2024. — №1. — С.18-22. URL: https://www.osp.ru/os/2024/01/13058259 (дата обращения: 21.09.2024).
- Александр Прозоров, Дмитрий Волков. Платформа непрерывной трансформации бизнеса // Открытые системы.СУБД. — 2023. — №1. — С.13-19. URL: https://www.osp.ru/os/2023/01/13056920 (дата обращения: 21.09.2024).