
 Дистилляция данных и знаний — это две разные концепции, которые имеют общую цель: снижение сложности при сохранении важной информации. В то время как дистилляция знаний фокусируется на переносе знаний из сложной модели в более простую, дистилляция данных фокусируется на извлечении репрезентативного подмножества данных из более крупного набора данных. Оба метода имеют важные приложения в корпоративной архитектуре и искусственном интеллекте и могут использоваться для повышения производительности и эффективности различных моделей и систем.
Дистилляция данных и знаний — это две разные концепции, которые имеют общую цель: снижение сложности при сохранении важной информации. В то время как дистилляция знаний фокусируется на переносе знаний из сложной модели в более простую, дистилляция данных фокусируется на извлечении репрезентативного подмножества данных из более крупного набора данных. Оба метода имеют важные приложения в корпоративной архитектуре и искусственном интеллекте и могут использоваться для повышения производительности и эффективности различных моделей и систем.
Целью данного исследования является предоставление анализа дистилляции данных и знаний в медицине, их важности, решаемых проблемах и связи с архитектурой единого семантического слоя.
Что такое дистилляция данных?
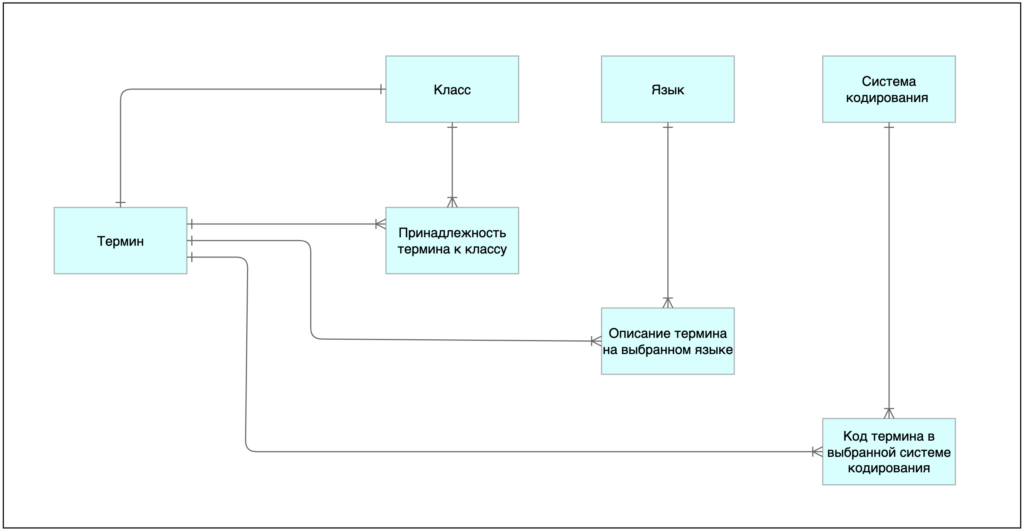
Дистилляция данных — это технологический подход, который включает в себя извлечение необходимой информации из больших разрозненных наборов данных, устранение шума, избыточности и неоднозначности, и сохранение в компактной машиночитаемой форме, что приводит к уточненному и стандартизированному представлению данных. Этот процесс позволяет более эффективно решать задачи семантической интеграции данных между различными системами, что в конечном итоге, позволяет медицинским работникам принимать более обоснованные решения, улучшая тем самым, качество оказания медицинской помощи пациентам.
Зачем нужна дистилляция данных?
В медицинской терминологии и управлении медицинскими записями дистилляция данных необходима по трем причинам:
- Информационная перегрузка. Огромный объем медицинских данных, генерируемых из различных источников, включая электронные медицинские карты (ЭМК), результаты лабораторных исследований и медицинские изображения, может быть подавляющим внимание. Дистилляция данных помогает отфильтровывать нерелевантную информацию, снижая когнитивную нагрузку на медицинских работников.
- Сложность данных. Медицинские данные часто сложны, с несколькими системами терминологии, системами кодирования и соглашениями о форматировании. Дистилляция данных упрощает эту сложность, обеспечивая бесшовную интеграцию и анализ данных из различных источников.
- Непоследовательная терминология. Медицинская терминология может быть непоследовательной, при этом для описания одного и того же понятия могут использоваться разные термины. Дистилляция данных помогает стандартизировать терминологию, гарантируя, что специалисты в области здравоохранения используют общий язык.
Проблемы, решаемые дистилляцией данных
Дистилляция данных решает ряд проблем в области медицинской терминологии и управлении медицинскими записями:
- Улучшенное качество данных. Устраняя ошибки, несоответствия и избыточность, дистилляция данных повышает точность и надежность медицинских данных.
- Расширенная поддержка принятия решений. Упрощенные и стандартизированные данные позволяют медицинским работникам принимать обоснованные решения, снижая риск неправильной диагностики или неправильного лечения.
- Оптимизированное распределение ресурсов. Анализ данных помогает выявлять закономерности и тенденции в медицинских данных, позволяя организациям здравоохранения более эффективно распределять ресурсы.
Связь с единым семантическим слоем
Единый семантический слой — это унифицированная структура, которая обеспечивает общее понимание медицинских терминов, их определений и взаимосвязей. Дистилляция данных тесно связана с единым семантическим слоем, поскольку она:
- Обеспечивает стандартизацию. дистилляция данных помогает стандартизировать медицинскую терминологию и концепции, приводя их в соответствие с принципами единого семантического уровня.
- Облегчает интеграцию. упрощая и стандартизируя данные, дистилляция данных обеспечивает беспрепятственную интеграцию различных источников данных, что является ключевым аспектом единого семантического уровня.
Этапы и компоненты процесса дистилляции данных
Процесс дистилляции данных, основанный на едином семантическом слое, включает следующие этапы и компоненты:
- Прием данных. Сбор медицинских данных из различных источников, включая электронные медицинские карты, результаты лабораторных исследований и медицинские изображения.
- Предварительная обработка данных. Очистка, фильтрация и нормализация данных для удаления ошибок, несоответствий и избыточности.
- Стандартизация терминологии. Преобразование локальной терминологии в стандартизированный словарь, совместимый с системами кодирования SNOMED CT, ICD-10 и другими.
- Извлечение терминов. Выявление терминов и их взаимосвязей в предварительно обработанных данных.
- Преобразование данных. Преобразование извлеченных терминов в стандартизированный формат, обеспечивающий интеграцию с другими источниками данных.
- Хранение данных. Хранение отобранных данных в централизованном репозитории, облегчающее доступ и анализ.
Преимущества дистилляции данных
К преимуществам процесса дистилляции данных следует отнести:
- Улучшенное качество данных. Повышенная точность и надежность медицинских данных.
- Расширенная поддержка принятия решений. Упрощенные и стандартизированные данные обеспечивают семантическую однородность, что позволяет принимать более точные решения.
- Оптимизированное распределение ресурсов. Выявление закономерностей и тенденций позволяет определить распределение ресурсов.
- Улучшение ухода за пациентами. Точная и своевременная информация обеспечивает лучшие результаты лечения пациентов.
Недостатки дистилляции данных
К недостаткам процесса дистилляции данных следует отнести:
- Сложность. Обработка данных требует значительных знаний в медицинской терминологии, анализе данных и разработке программного обеспечения.
- Ресурсоёмкость. Процесс может занять большое количество времени и потребовать значительных вычислительных ресурсов.
- Риск потерь информации. Чрезмерное упрощение сложных данных может привести к потере информации, которая может оказаться значимой в течение всего срока хранения данных.
Что такое дистилляция знаний?
Дистилляция знаний, также известная как дистилляция моделей или обучение учителей и учеников, представляет собой метод, используемый для передачи знаний из сложной, большой нейронной сети (модель «учителя») в меньшую, более простую нейронную сеть (модель «ученика»). Целью дистилляции знаний является сохранение производительности модели учителя при одновременном снижении вычислительных требований и размера модели ученика. Это достигается путем обучения модели ученика для имитации поведения модели учителя, а не обучения ее с нуля на исходных данных.
В дистилляции знаний модель учителя обычно является предварительно обученной, высокопроизводительной моделью, которая научилась распознавать закономерности в данных. Модель ученика, с другой стороны, является меньшей, более эффективной моделью, которая обучена воспроизводить выходные данные модели учителя. Таким образом, модель ученика учится фиксировать существенные особенности и закономерности в данных, не требуя того же уровня сложности, что и модель учителя.
Отличия дистилляции знаний от дистилляции данных
При общих целях, существуют два принципиальные отличия между дистилляцией данных и знаний:
- Фокус. Дистилляция знаний направлена на передачу знаний из модели учителя в модель ученика, в то время как дистилляция данных направлена на извлечение репрезентативного подмножества данных из более крупного набора данных.
- Методы. Дистилляция знаний обычно включает в себя обучение модели ученика для имитации поведения модели учителя, в то время как дистилляция данных включает в себя выбор репрезентативного подмножества данных с использованием различных методов, включая методы машинного обучения, такие как кластеризация или снижение размерности.
Заключение
Дистилляция данных и знаний — критически важные процессы в медицинской терминологии и управлении документами, позволяющие специалистам здравоохранения принимать обоснованные решения, повышать качество оказания медицинской помощи пациентам и оптимизировать распределение ресурсов. Стандартизируя медицинские термины, дистилляция данных соответствует принципам единого семантического слоя, способствуя бесшовной интеграции различных источников данных. Хотя существуют проблемы, связанные с дистилляцией данных, ее преимущества намного перевешивают ее недостатки, что делает ее неотъемлемым компонентом современных медицинских ИТ-систем. Поскольку объем и сложность медицинских данных продолжают расти, дистилляция данных будет играть все более важную роль в улучшении результатов здравоохранения и оптимизации распределения ресурсов.